
一、内存布局模型
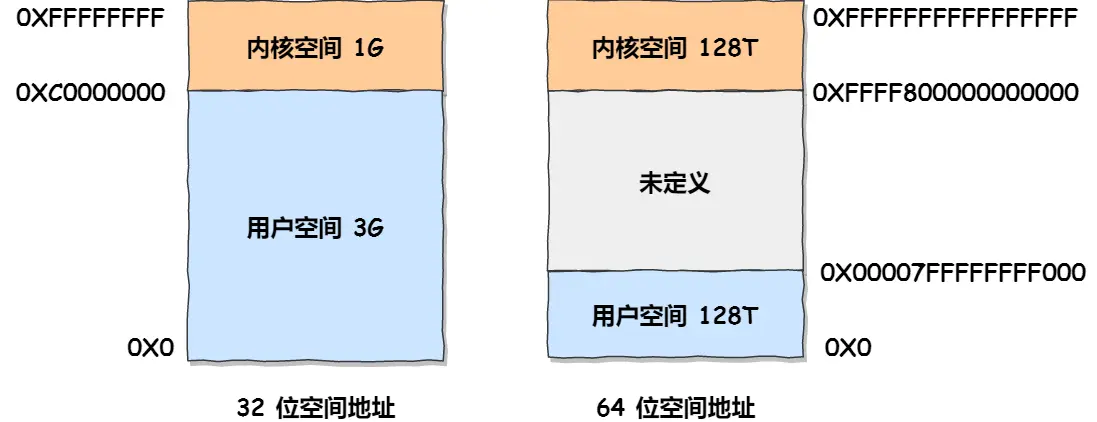
在 Linux 操作系统中,通过 虚拟地址空间 将每个进程的内存视图隔离,并通过页表机制映射到屋里内存,从而实现了内存的高效管理和安全性,这种设计使得操作系统可以有效地管理有限的物理内存资源,并且为进程提供了一个统一的、隔离的内存环境。虚拟地址空间的内部又被分为 内核空间和用户空间 两部分,不同位数的系统,地址空间的范围也是不同,如下 32 位和 64 位系统:
上图中我们可以得到一些信息:
- 32 位系统的内核空间占用 1G ,位于最高处,剩余的 3G 是用户空间。
- 64 位系统的内核空间和用户空间都是 128T ,分别占据内存空间的最高和最低处,剩下中间部分是未定义的。
每个进程都有各自独立的虚拟内存,在用户态时只能访问用户空间内存,只有进入内核态后,才可以访问内核空间的内存。但是每个虚拟内存中的内核地址,关联的都是相同的物理内存,这样,进程切换到内核态后,就可以很方便的访问内核空间内存。
关于内核空间,这里不再赘述,本章节主要探索用户空间的划分情况,以 32 位系统为例:
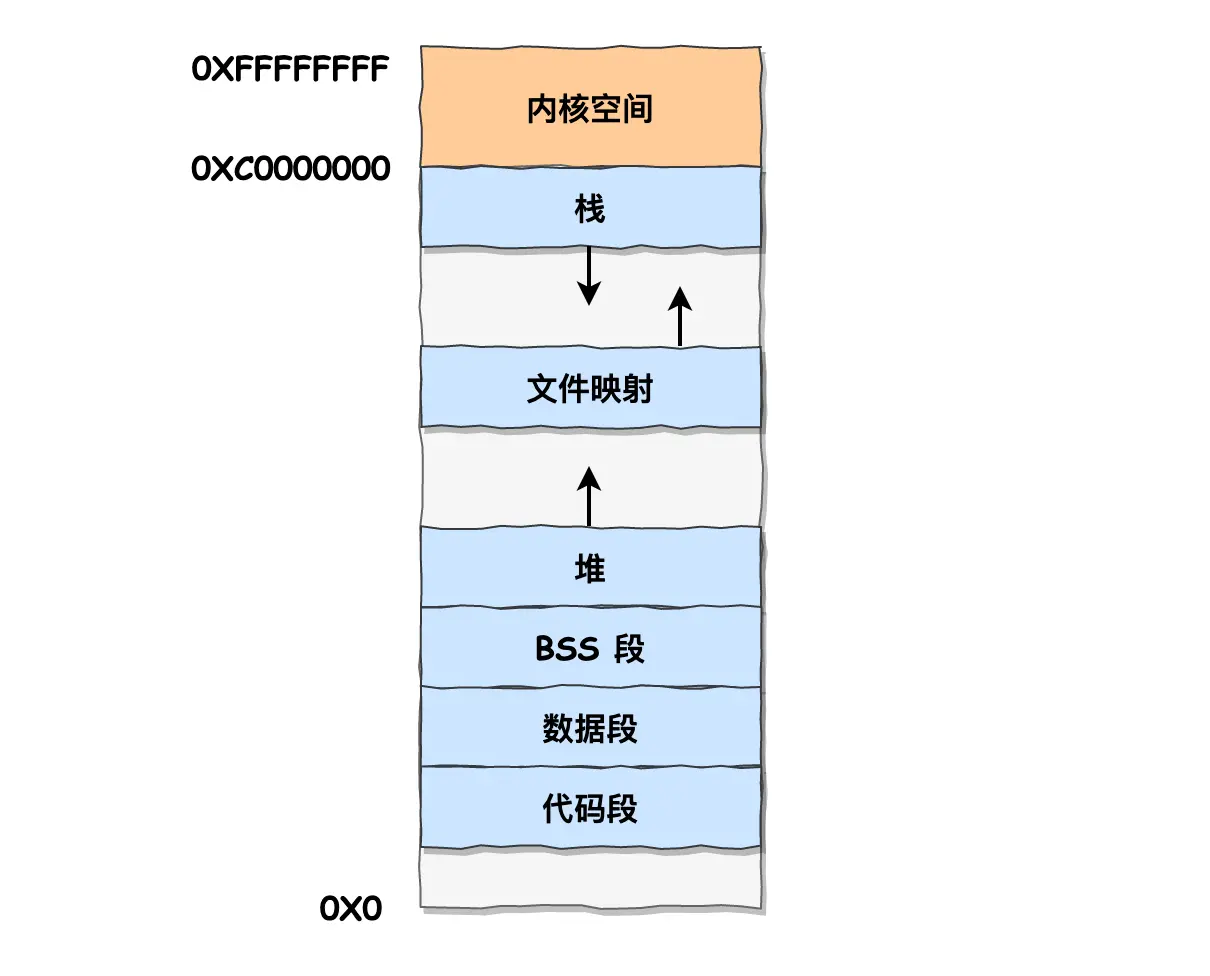
在用户空间内存中,从 低到高 划分了 6 种不同的内存段:
- 代码段(Text Segment): 存储程序的可执行代码
- 数据段(Data Segment): 包括已初始化的静态常量和全局变量
- BSS段(Block Started by Symbol): 包括未初始化的静态变量和全局变量
- 堆(Heap): 动态分配的内存区域,用于存储动态分配的对象和数据结构
- 栈(Stack): 用于存储函数调用时的局部变量、函数参数以及返回地址等
- 文件映射段: 包括动态库、共享内存等,从低地址开始向上增长
在上面的内存布局最下方有一段保留的内存空间(灰色部分),之所以要有这样一个保留区是因为在大多数的系统中,认为比较小数值的地址不是一个合法的地址,例如,在 C 语言代码中将无效的指针赋值为 NULL ,因此这里出现一段不可访问的内存保留区,防止程序因为出现 bug ,导致读或者写一些小内存地址的数据,而使程序跑飞。
在这几个内存段中,堆和文件映射段的内存是动态分配的,比如说,使用 C 标准库的 malloc() 或者 mmap() , 就可以分别在堆和文件映射段动态分配内存。
二、函数与栈
2.1 栈方向问题
这里需要解释一个问题,就是为什么栈是从高位到低位分配内存? 其实这种设计可以使得堆和栈能充分利用空闲的地址空间: 在虚拟地址空间的分配规则中,每一个可执行 C 程序中,从低地址到高地址依此是 text、data、bss、堆、栈等这几个段; 其中堆和栈之间有很大的地址空间空闲着,在需要分配空间时,堆向上涨,栈向下涨。但如果栈向上涨的话,就必须要指定栈和堆的一个严格分界线,但不同的应用程序使用的栈空间不同,从实际来说根本没有办法给出合理的界限。
2.2 函数入/出栈原理
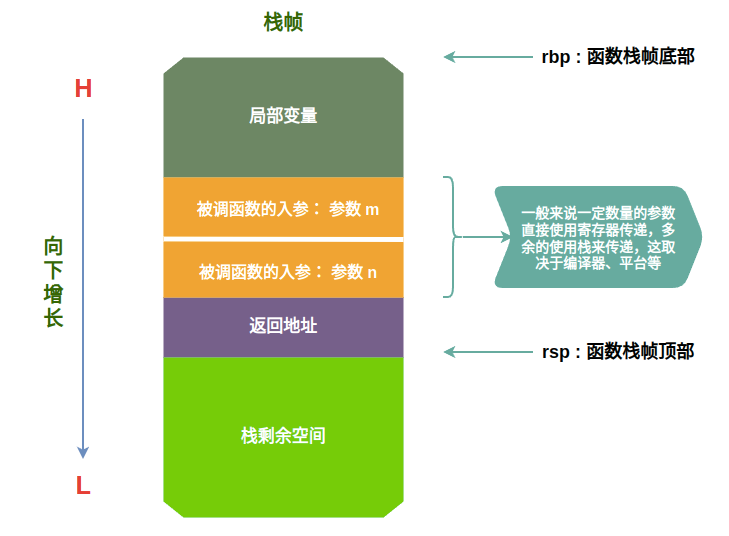
栈 是函数调用的核心机制,每一次函数的调用,都会在栈上维护一个独立的 栈帧 ,而当函数调用结束时,就会从栈上将对应的 栈帧 移除,换言之函数的开始和结束,都是一个个栈帧入栈和出栈的过程,效果如下所示:

那么这个 栈帧 里面到低包含什么内容呢?一般来说每个独立的帧栈主要包括:
- 函数的返回地址和参数,返回地址是指被调函数下一条指令,并非是指函数的返回值
- 临时变量: 包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 函数调用的上下文,rbp 和 rbp 等
接下来以一个简单的 C 代码来做说明:
|
编译为可执行程序后,使用 gdb 启动调试模式,这里我使用到了一个插件 gdb-peda,这个插件能更加清晰便捷的展示相关的信息,下面就这个插件展示的相关内容做简要介绍:
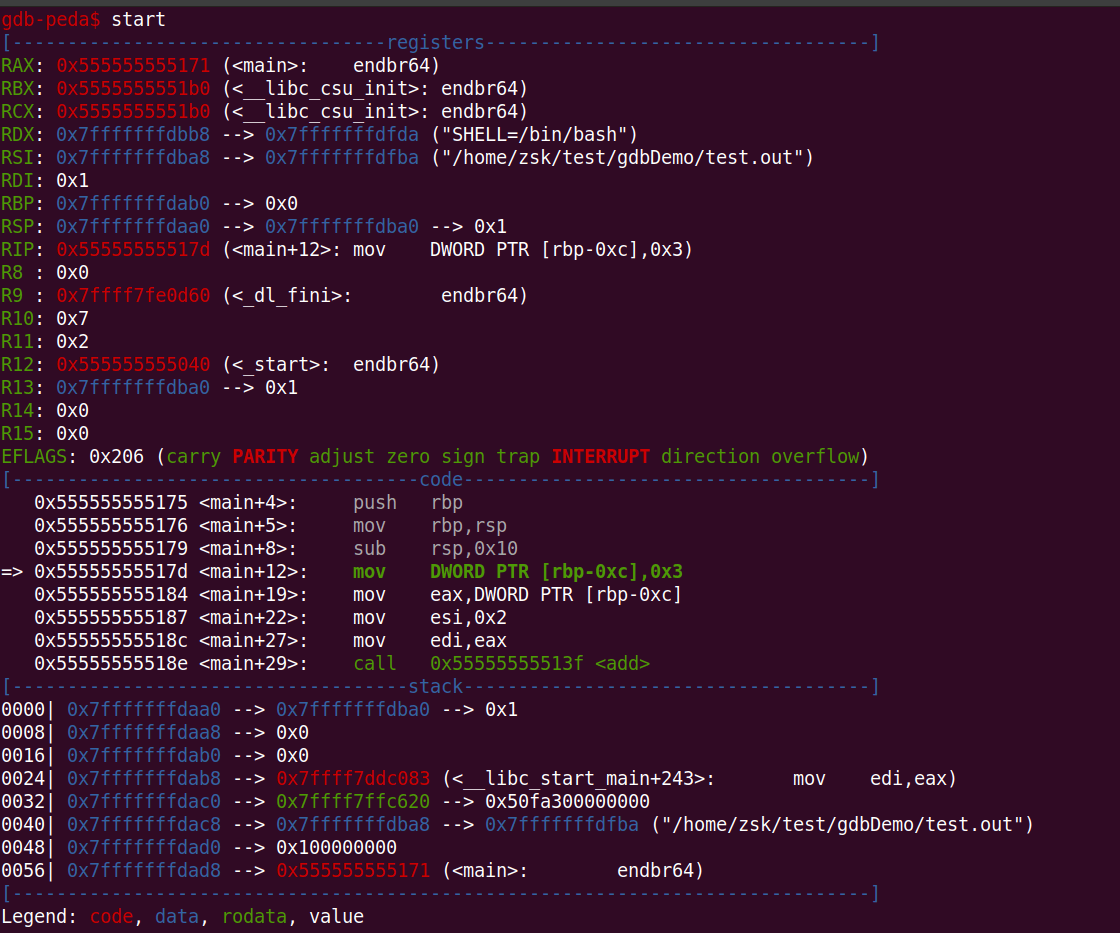
整个界面划分为三个区域:
- register : 寄存器区,用于显示各个寄存器的值
- code : 汇编代码区,左侧箭头表示执行到的当前汇编指令,可以使用 disassemble 指令查看完成汇编代码
- stack : 栈区,显示栈内数据内容
我们在调试时,可以使用 ni、si 指令,用于一步一步执行汇编指令。因为 main 函数并非程序的真正入口,当使用 start 指令启动调试模式时,其实已经进入到了 main 函数的执行环境中了,因此没有办法演示 main 函数的最开始分配栈空间相关部分,表现在上图 code 区中左侧 => 指向的是第四条指令,而非第一条指令。
当然也可以使用 b *_start 这样的指令断点执行,或可以观察到 main 函数的调用过程。
上图中我们可以得到如下信息:
- 当前 栈基址(rbp) 为 0x7fffffffdab0
- 当前函数分配了 16 字节栈空间,所以 栈顶(rsp) 为 0x7fffffffdaa0
- add 函数参数较少,所以只用 esi 和 edi 两个寄存器保存参数
当执行到 add 函数时,调试数据如下所示:
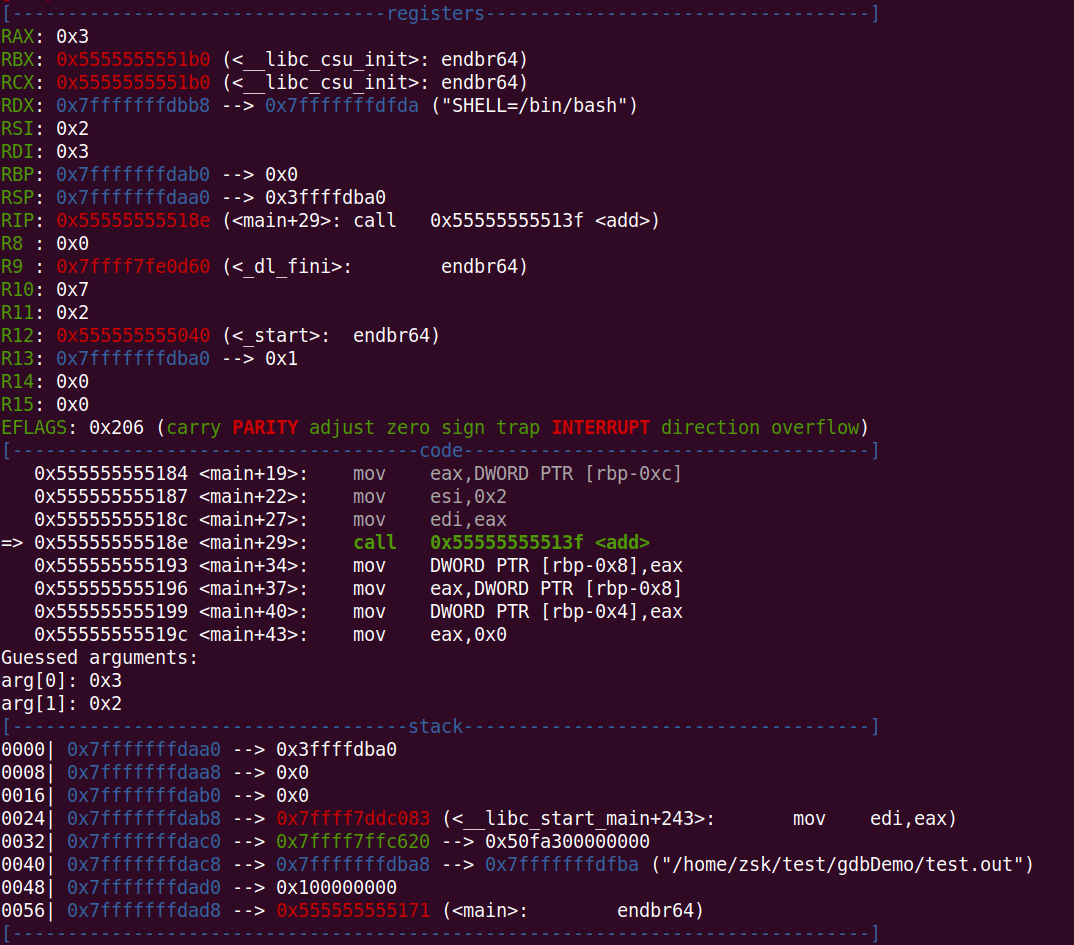
我们可以看到栈中内容并没有多大变化,栈顶指针的值变为 0x3ffffdba0 ,这个属于脏数据,并没有实际意义。那么当进入此函数时,我们可以猜想栈的内容是什么?函数的调用过程中,栈内容主要变化如下:
- 将该函数的下一条指令压栈
- 将旧 rbp 值压栈
- 为临时变量分配栈空间等
使用 disassemble 指令查看完整的汇编指令如下:
Dump of assembler code for function main: |
可以看出调用 add 指令的下一条指令(返回地址) 为 mov DWORD PTR [rbp-0x8],eax,其对应的地址为 0x0000555555555193;所以可以猜想栈内容如下所示:
...... --> //分配的临时变量栈空间,具体视 add 函数内部变量而定 |
现在使用 si 指令进入 add 函数,观察是否和猜测的一致:
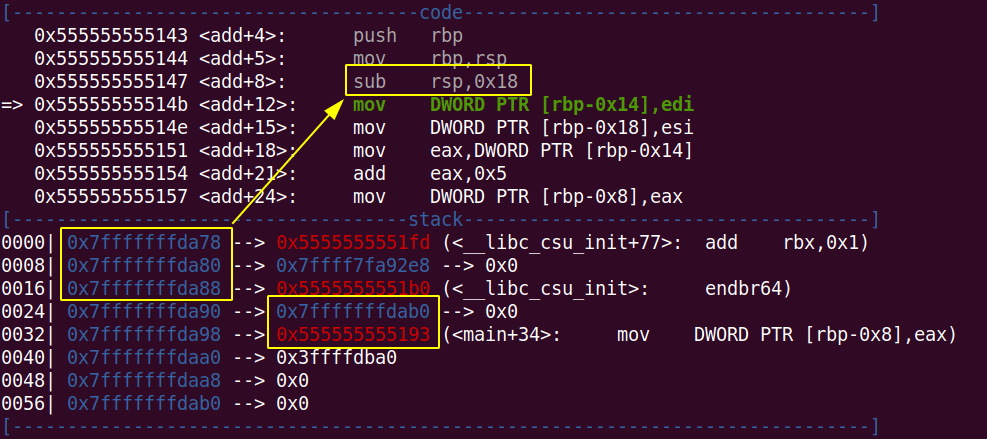
可以看到图中的栈内容变化和我们猜测的基本一致,0x7fffffffda78 ~ 0x7fffffffda88 这 24 个字节是 add 函数为临时变量分配的栈空间,这里要做说明的是在图中这 24 个字节中看起来存储的是一些数据,这些属于脏数据,并没有实际意义,在随着指令的进一步执行,这些空间就会被相应的值覆盖。
三、工程实践调试方法
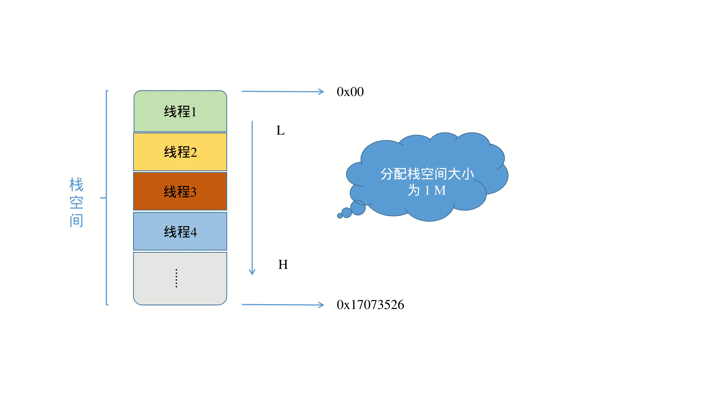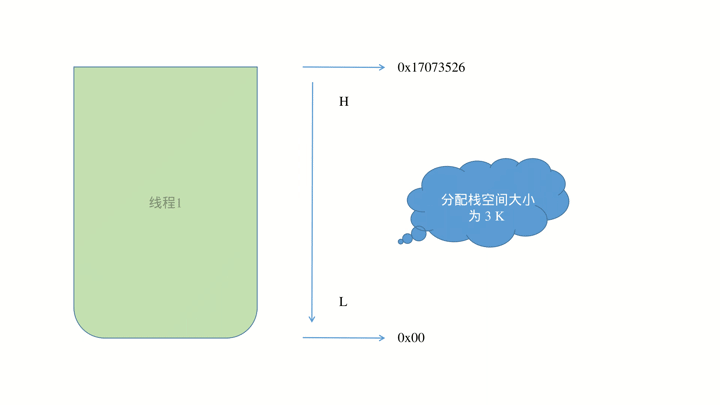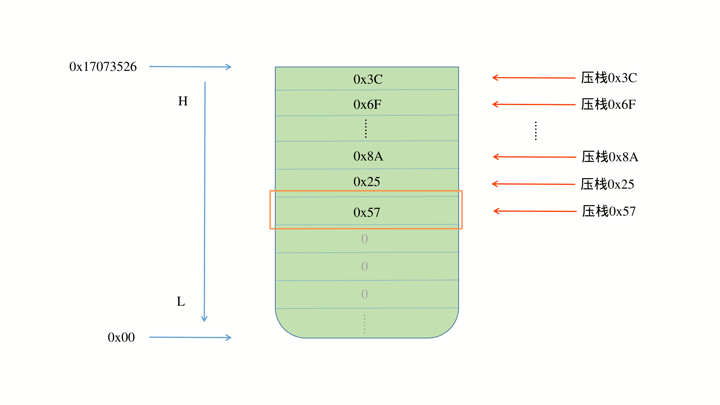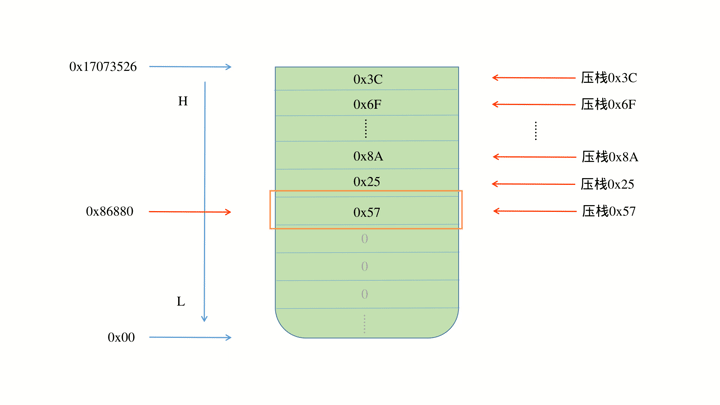
了解了上面的一些原理性的内容之后,在面对程序栈内存优化相关问题时就会游刃有余,例如笔者在工作中遇到如下一个问题:分配一整块空间给作为栈空间给多个线程使用,那么这块空间应该分配多大才合适呢?太大势必造成资源浪费,太小又会导致程序的崩溃。这个问题的难点在于如何确定每个线程所占用的最大的栈空间,首先来看一下示意图:
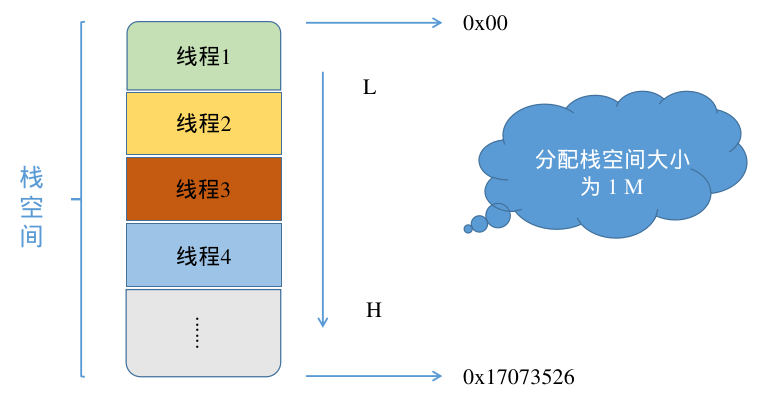
假如这块 栈空间 一共是 1M 大小,为了清晰的说明问题,这里假设地址从低到高为 0x00 ~ 0x17073526 ,这块内存被多个线程共同使用。
这块内存在分配时会全部初始化为 0, 而每个线程都在这块空间的不同位置作为 栈基址(rbp) ,这是我们调试的前提。这样当各个线程运行起来时,会根据需要在各自的栈空间内不停的入栈出栈,相应的栈空间的值就会被不停的覆盖,因此在长时间运行之后,在栈空间中由高到低最后一个非零 0 的地址即为此线程所能访问到的最远距离,那么这中间的偏移空间即为该线程所占用的最大空间,动态效果图如下所示:
在动图中以第一个线程来做说明,给此线程一共分配 3K 大小的内存,那么在栈空间中地址范围为 0x00 ~ 0x86880 ,又因为栈的使用是遵循从高位到低位的规律,所以在数据压栈时也是从最高位开始,如下图所示:
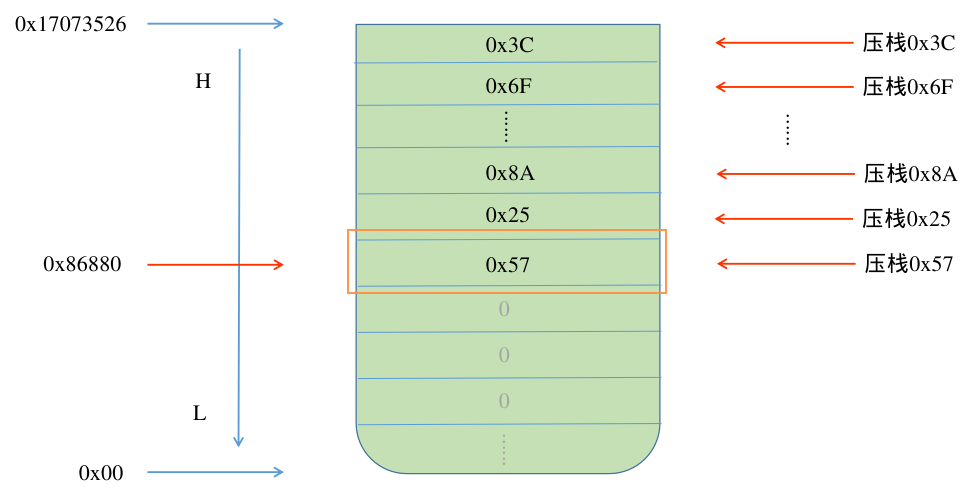
可以看到在程序运行过程中,栈空间并不会自主的清零,而是采用覆盖的策略,因此在 0x86880 这个位置就是这个线程在运行时所能达到的最远的地址,那么用 起始地址与此地址作差 即可得出此线程的剩余空间,进而估算出此线程所需要的最大栈空间。
3.1 栈内存优化
造成栈内存消耗过大的主要原因是在函数内存在比较大的临时变量,比如大结构体、大数组等,那么我们需要一种方法来找到这些包含大数组和大结构体的函数,这里还以多线程为例: 假如存在一个线程,起始地址为 0x555555d3b580 ,分配的栈空间大小为 20k 。首先要在 gdb 环境下运行一段时间程序,这样尽可能的保证程序可以执行到最远能访问的地址。现在要确认的就是这个最远的地址,我们可以这样做:
- 暂停程序(ctrl+c),使用如下指令查找最后一个 非0 的地址
// 这表示显示 0x555555d3b580 + 1024*11 地址下128个地址的值,一共分配了20k的空间,这里需要一点一点尝试 |

这里可以看到在 0x555555d4d3c0 这一行中存在最后一个非0的位置,那么此处即为程序所能访问的最远地址,此地址为 0x555555d4d3c0 偏移 8个字节得到的 0x555555d4d3c8
- 观测这个地址,重新执行程序(r)
watch *(unsigned int*) 0x555555d4d3c8 |
重新运行,执行到断点处,bt 指令查看相应的堆栈调用信息:
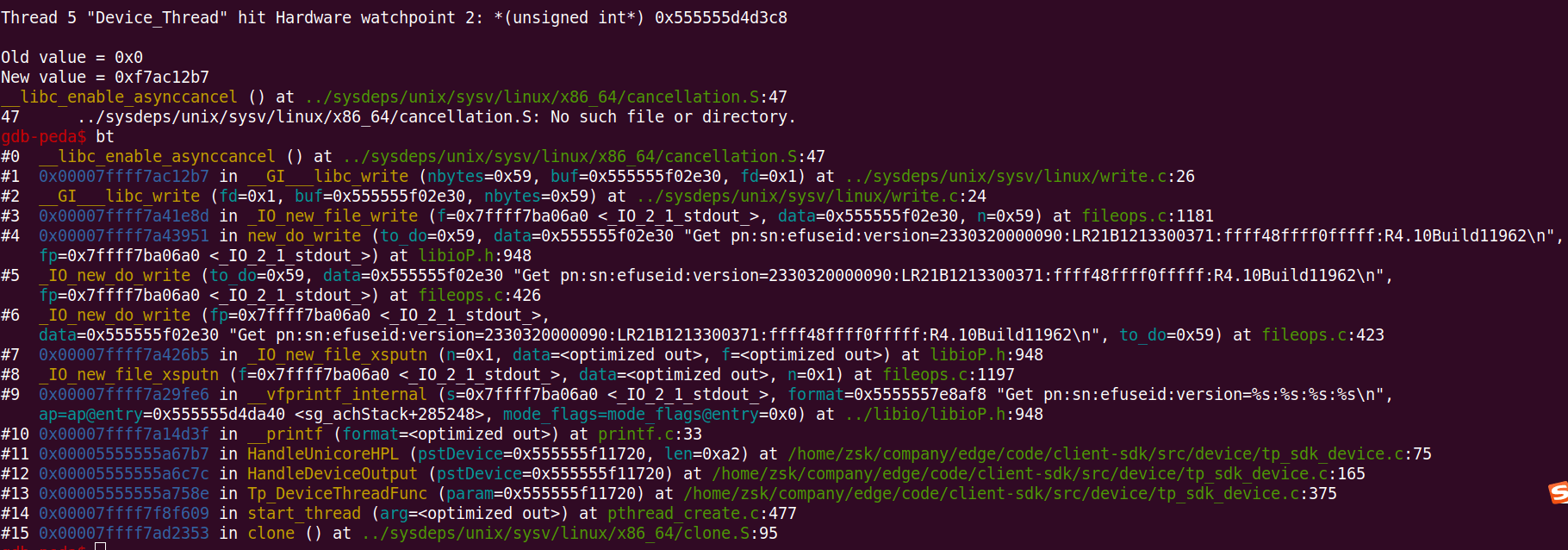
这样在使用 [up]、[frame n] 等指令切换到不同函数调用栈中,打印栈顶指针 rsp ,这样当 rsp 的值有明显变化时,说明当前函数内存在大的临时变量等,以此做相应的优化处理。